- AI
- BPO
- BtoBサービス
- Criteo広告
- DSP
- DXリテラシー研修
- EFO
- ERP
- Eve
- Facebook広告
- Google広告
- Google解析・分析ツール
- HRTech
- HubSpot
- IoTプラットフォーム
- KGI
- KPI
- Line
- LINE広告
- LPO
- SEO
- shopify
- twitter広告
- Webサイト
- Web制作会社
- Yahoo!広告
- Yahoo広告
- アクセス解析の基本の「き」
- アップデート
- アフィリエイト広告
- インハウス
- エンジニア向けスキルシート
- エンジニア育成
- オンライン学習
- カスタマーサクセスDX
- クラウド会計ソフト
- コロナウイルス
- タスク管理
- テレワーク
- ディスプレイ広告
- デジマの教科書
- データ分析
- ノーコード
- ビジネス
- フィンテック
- マッチング
- リスティング広告
- リスティング広告運用の基本の「き」
- 不動産DX
- 介護DX
- 冠婚葬祭DX
- 副業
- 動画広告・動画配信
- 勤怠DX
- 医療・介護DX
- 協業
- 営業DX
- 小売・飲食DX
- 広告DX
- 建設・製造DX
- 支援サービス
- 教育・学習DX
- 新人デジマ女子のラクする仕事帖
- 旅行DX
- 景表法違反
- 法律相談
- 生成AI
- 統合仮想化ソリューション
- 薬機法違反
- 行政・自治体
- 製薬業界DX
- 観光・宿泊DX
- 請求書DX
- 議事録
- 財務・会計DX
- 資産管理DX
- 農業DX
- 運輸・物流DX
FRAIM株式会社、自然言語処理を中心としたAIアルゴリズムとエディタ技術のライセンス提供を開始
FRAIM株式会社(本社:東京都港区南青山 代表取締役社長:堀⼝圭 以下:FRAIM)は2月1日、自然言語処理を中心としたAIアルゴリズム、リコメンド・検索アルゴリズム、編集時間を大幅に削減するエディタなどの独自技術を、顧客の既存システムのバージョンアップや新規プロダクトのコア機能として活用可能なライセンスとして提供開始を発表した。
目次
FRAIM株式会社が提供する4つのライセンス
提供されるライセンスは、以下の4つである。
- 高速オンラインエディタ(FRAIM Rich Editor)
- 独自アルゴリズムによって実現した文章のAI検索・サジェストエンジン(FRAIM Paragraph Suggest)
- ドキュメントから必要な情報を自動抽出するエンジン(FRAIM Data Extraction)
- スキャンされた文章の画像データを解析するエンジン(FRAIM Scan Parser)
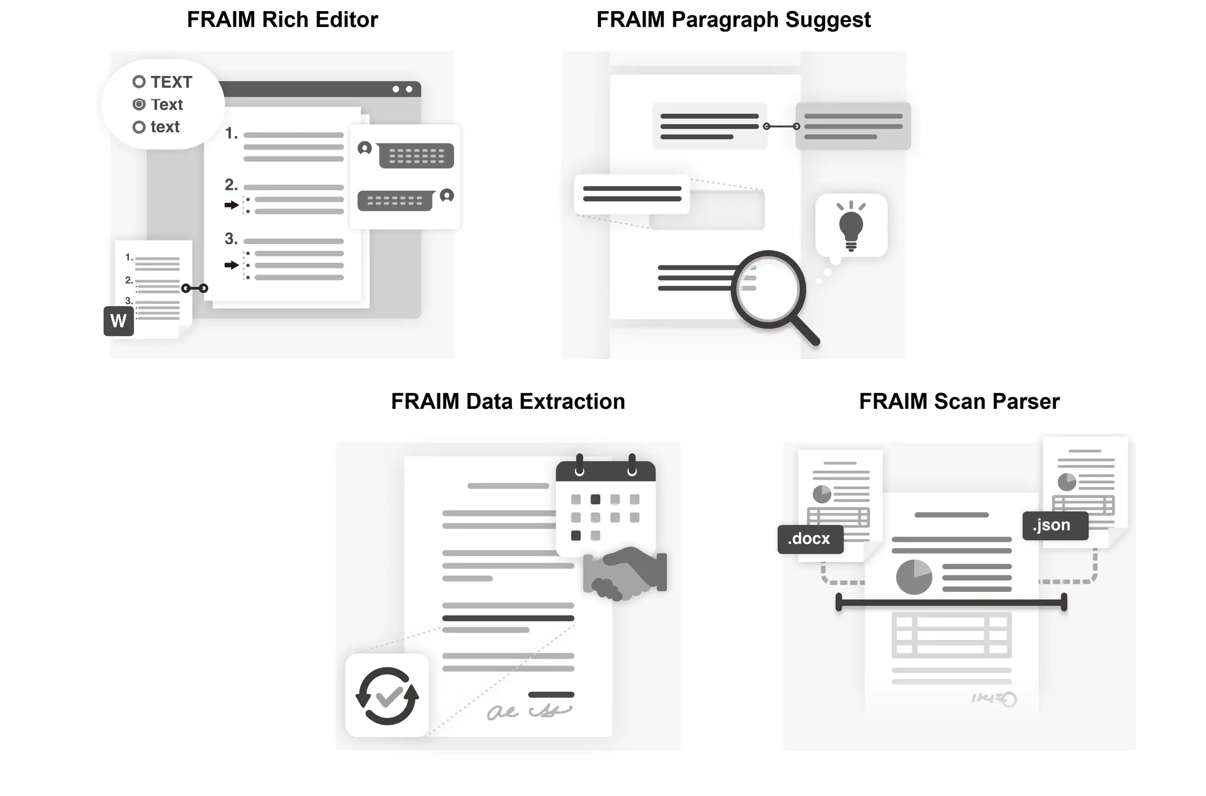
FRAIM Rich Editor
特許技術により、インデントやナンバリングの自動補正、表記揺れ検出などを可能にしたブラウザ上で高速に動作するオンラインエディタ。
オンラインチャットとの組み合わせや、Wordとの相互変換にも対応しており、さまざまなユースケースでドキュメント作成の業務効率化を実現。
FRAIMが提供する各種ソリューションとの柔軟な組み合わせが可能である。
FRAIM Paragraph Suggest
特許技術に基づく独自アルゴリズムによって実現した、文章のAI検索・サジェストエンジン。類似パラグラフや類似表現の自動サジェストのほか、不足パラグラフの自動サジェストなどが可能。
利用するドキュメントの種類に最適な自動サジェストを行うために自動学習機能が搭載されており、さまざまなユースケースに適用できる。
FRAIM Data Extraction
ドキュメントから必要な情報を自動抽出するエンジン。契約書からの情報抽出に関しては高精度かつバリエーション豊かな情報抽出を実現している。
「契約日」や「契約開始日/終了日」といった比較的シンプルな情報だけでなく、「契約自動更新の条件」などの文章で表現されるような複雑な情報であっても高精度で自動抽出可能。
FRAIM Scan Parserとの組み合わせ利用により、紙のスキャンデータからの情報抽出も可能になる。
FRAIM Scan Parser
スキャンされた文章の画像データを解析するエンジン。日/英に対する高精度なテキスト認識(手書き文字を含む)、文章の段組判定や印影除去、不要な改行除去による文章の再現などを実現する。
さらに解析結果をdocxファイルやJSONファイルに変換でき、さまざまなシステムへの適用が容易。
変換されたファイルはFRAIM Rich Editorでの編集や、FRAIM Data Extractionでの情報抽出と連携可能なため、DX導入に非常に有効なソリューション技術の一つとなる。
<リンク>
https://prtimes.jp/main/html/rd/p/000000036.000037680.html
投稿者プロフィール



おすすめ記事Recommended Articles
-

年末年始にWeb広告を配信するメリットとは?おすすめ業界もご紹介
2023.11.02 WEBマーケティング -
インフルエンサーマーケティングとは?メリット・デメリットや注意点
2023.04.20 WEBマーケティング -
Google検索結果から削除したい!サーチコンソールで素早くページを削除する方法
2021.11.12 WEBマーケティング -

リスティング広告のターゲット選定方法を解説!
2021.04.03 WEBマーケティング -
リスティング広告の予算はどう決めればいいの?
2021.04.02 WEBマーケティング -
消費税総額表示義務、ネット広告・アフィリエイト広告のチェックポイント
2021.03.07 WEBマーケティング
DXニュースについてABOUT DX NEWS
デジタルトランスフォーメーションを推進するにあたって参考となる国内外の事例、
デジタルマーケティングを自社内で行うインハウス化に関するお役立ち情報を提供しています。